1. Introduction
Nonparametric statistics is a field that has been rapidly developing over the last decade. Its development has been aided by the various benefits it has relative to classical statistical techniques:
- We can relax assumptions on the probability distribution of the data. Most notably, the normality.
- There are cases in which classical procedures are neither applicable nor interpretable but a nonparametric one is.
- Modern computing has empowered many of these computationally expensive techniques.
So far, when approaching statistics problems, we’ve assumed the distribution of data. However, we rarely ever understand the data enough to confidently assume a distribution. We will cover Kernel Density Estimation (KDE), a non-parametric estimation technique for any distribution f(x). We will start with an explanation and mathematical form of a kernel density estimator, go over its properties, and touch on the burgeoning field of bandwidth selection.
2. History
The concept of KDE was created by Parzen (1962) and Rosenblatt (1956) in their independent works, so it is also called Parzen-Rosenblatt window method in other fields such as signal processing and econometrics.
3. Some Intuition
The Histogram
Non-parametric density estimation may sound very alien but in fact it’s so commonplace that we’ve already seen it countless times! In high school, and even earlier, we’ve come across the \(\textbf{histogram}\). Turns out, they are non-parametric density estimators.
We split our data into into \(K\) equally sized bins/intervals with boundaries \(a_0, a_1, \ldots, a_{K}\) and estimate the density in bin i as the proportion of observations that fall within \((a_{i-1}, a_{i}]\). Let \(n_i\) be the number of observations within interval \((a_{i-1}, a_{i}]\) and \(K\) be the number of bins, for a histogram from distribution \(X\) with sample size \(N\):
\[\begin{equation} \hat{f}(s) = \displaystyle \frac{1}{N}\sum_{i = 0}^{K-1}\frac{n_i}{a_i - a_{i - 1}}I_{(a_{i - 1}, a_i]}(s) \end{equation}\]However, there are problems with this. First, histograms tend to be blocky and sensitive to bins chosen.
some_data <- rchisq(n = 100, df = 5)
hist_bins <- function(data, bins) {
ggplot(mapping = aes(x = data, y=..density..)) +
geom_histogram(bins = bins, fill = "darkorchid4") +
ggtitle(sprintf(fmt = "%i bins", bins))
}
grid.arrange(hist_bins(some_data, 10),
hist_bins(some_data, 20),
hist_bins(some_data, 40),
hist_bins(some_data, 80), nrow=2)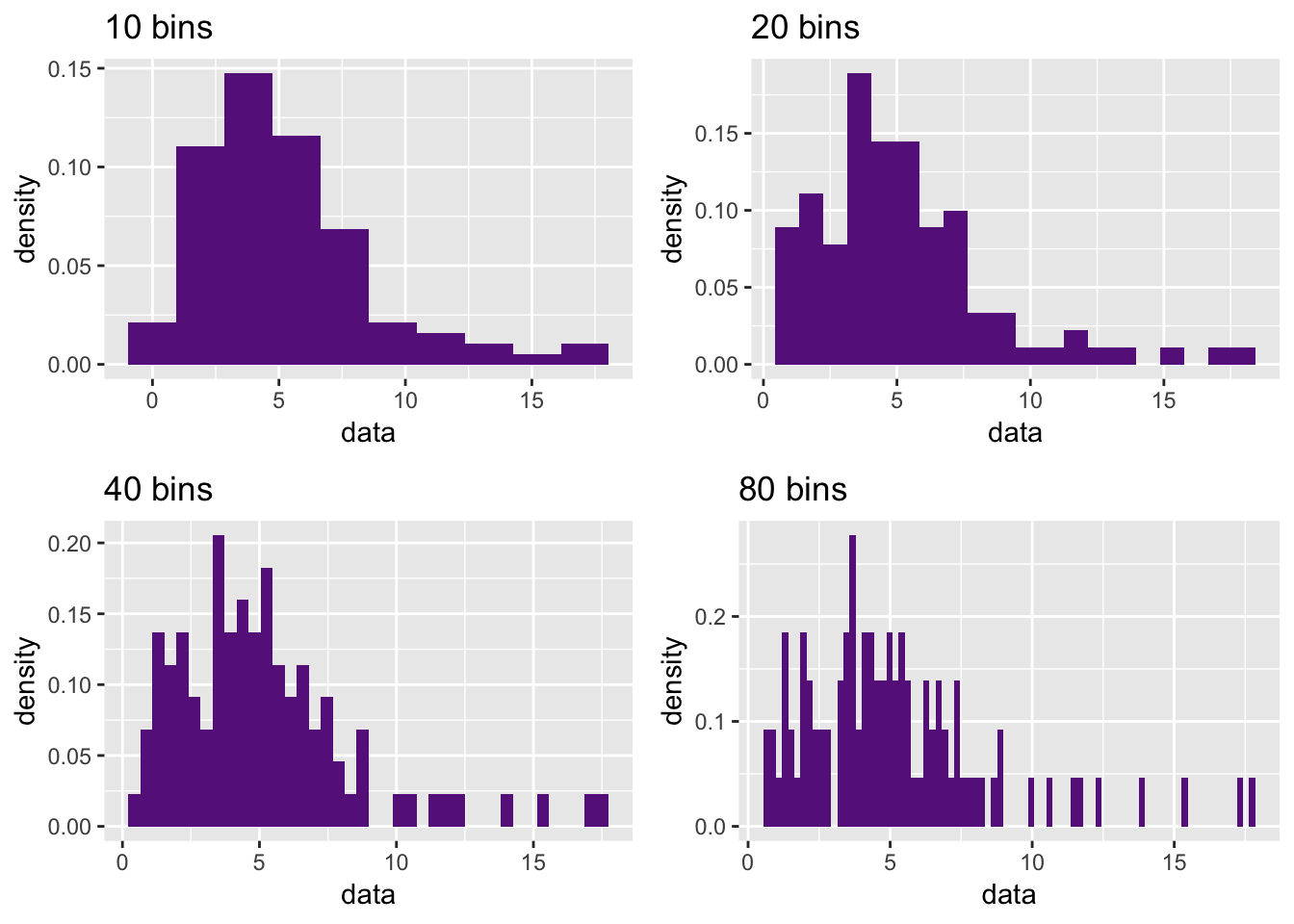
Also, histograms are inherently local; I can have an observation \(x = 4.99999\) not counted in interval \([5,6]\).
Kernel Density Estimation
A kernel density estimate, \(\hat{f}_N(s)\), looks at some some point \(s\) and the window \([s - h/2, s + h/2]\), where \(h\) is chosen bandwith, and counts the observations in the window.
\[\begin{align} \hat{f}_N(s) &= \frac{1}{N}\displaystyle \sum_{i = 1}^{N} \frac{1}{h}I_{[s - h/2, s + h/2]}(X_i) = \frac{1}{Nh} \sum_{i = 1}^{N}I_{[-h/2, h/2]}(X_i - s) \nonumber \\ &= \frac{1}{Nh} \sum_{i = 1}^{N}I_{[-1/2, 1/2]}\left(\frac{X_i - s}{h}\right) \end{align}\]We transform the initial equation with \(X_i\) into a “distance” of surrounding X_i away from our point of interest s weighted by bandwidth, \(\frac{X_i - s}{h}\). Thus, instead of fixed bins, we have a moving window and can weigh \(x = 4.99999\) accurately. However the roughness remains due to weighing each point in the window equally. You can think of a kernel function as a weighting function. Now, instead of weighing all distances from \(s\) the same, we can apply a smooth kernel function such as a Gaussian (normal) function which will weight smaller distances more and larger distances less towards the density at \(s\).
\[\begin{equation} \hat{f}_N(x) = \frac{1}{Nh} \sum_{i = 1}^{N} K\left(\frac{x - X_i}{h}\right) \end{equation}\]Above, \(K\) is our kernel/weighting function. The gaussian kernel function is very apparent in this low bandwidth (\(h=0.3\)) computation below. We look at a \(N = 100\) sample from Binom\((100, 0.5)\).
binom_data <- rbinom(n = 10000, size = 20, prob = 0.5)
ggplot(mapping = aes(x = binom_data)) +
geom_histogram(mapping = aes(y = ..density..), bins = 10, fill = "darkorchid4") +
geom_density(kernel = "gaussian", bw = 0.3, color = "#d2bf55", size = 1)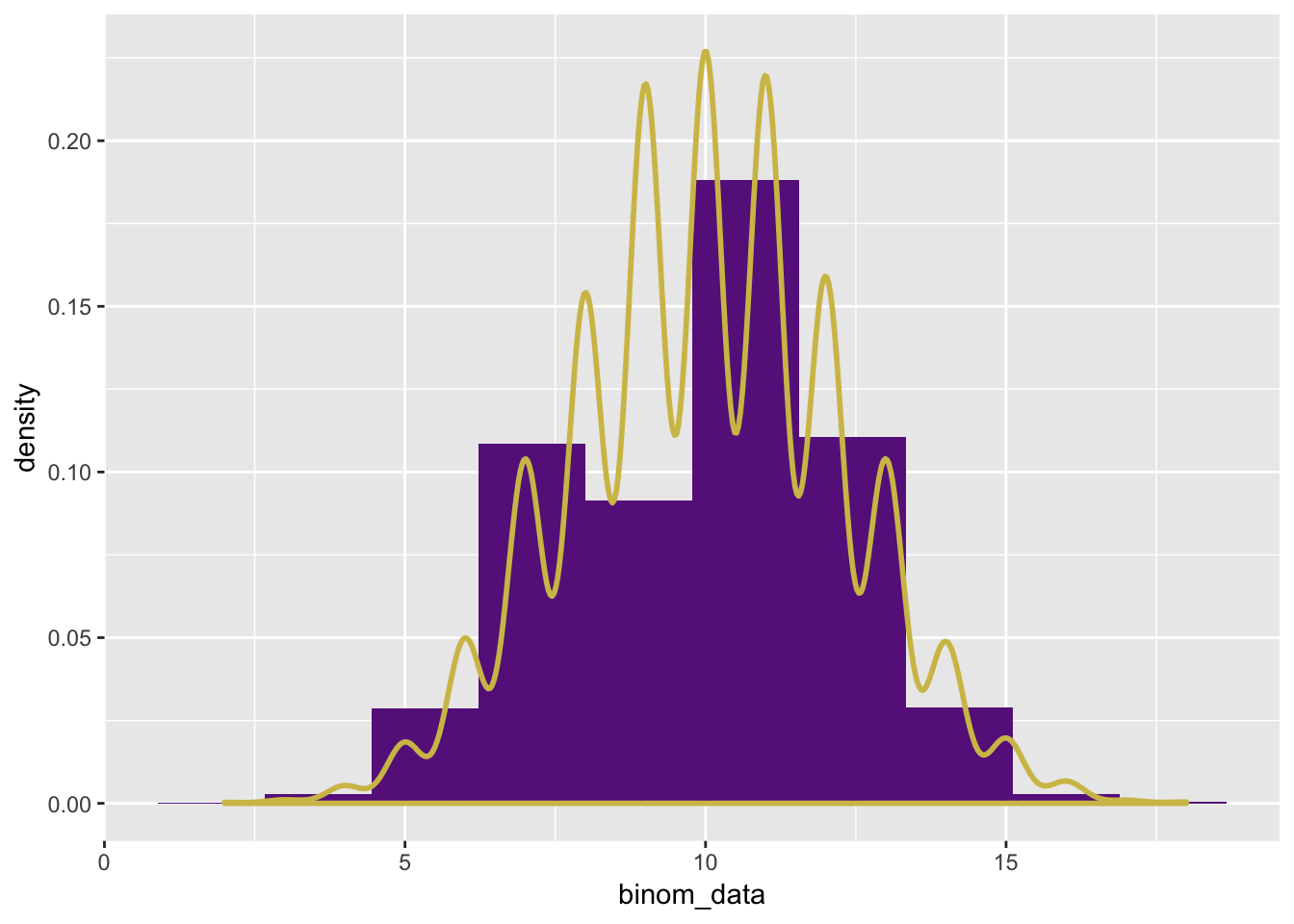
4. Theory and Properties
To allow for our analysis of KDE properties, we will outline a few rules about the Kernel and underlying density function.
- Kernel function \(K\): is symmetric about 0, \(\int_{\Omega_X} K dx = 1\), and \(\lim_{x\to-\infty} K(x)= \lim_{x\to\infty} K(x) = 0\)
- \(\int xK(x)dx < \infty\) and \(\int |x|(K(x))^2dx < \infty\)
- PDF \(f\): \(\mathbb{R} \rightarrow \mathbb{R}\) is Lipschitz Continuous, \(\exists M\in\mathbb{R}, |f(x) - f(y)| \leq M|x - y|, \forall x, y \in \mathbb{R}\)
Applications of assumptions will be notated in brackets (i.e: [1]). Proof is adapted from Wasserman (2006) and simplified.
Bias
As with most estimators, we want to account for bias. For \({X_1, X_2, \ldots, X_N} \overset{iid}{\sim} f\), the expected value of the kernel density estimate at \(s\): \[ \mathbf{E}[\hat{f}_N(s)] = \mathbf{E}\left[\frac{1}{Nh} \displaystyle \sum_{i = 1}^{N} K \left( \frac{X_i - s}{h}\right) \right] = \frac{1}{h}\mathbf{E}\left[K \left( \frac{X - s}{h}\right) \right] = \frac{1}{h} \int K\left( \frac{x - s}{h}\right) f(x) dx \] We set \(u = \frac{x - s}{h}\), substitute, and apply a \(2^{nd}\) order Taylor series expansion for \(f(hu + s)\) about \(h = 0\):
\[\begin{align*} \mathbf{E}[\hat{f}_N(s)] &= \frac{1}{h} \int K\left(u\right) f(hu + s) h du = \int K\left(u\right) f(hu + s) du \\ f(hu + s) &= f(s) + \frac{f'(s)}{1!}(u)(h-0) + \frac{f''(s)}{2!}(u^2)(h-0)^2 + o(h^2) \\ &= f(s) + huf'(s) + \frac{h^2u^2}{2}f''(s) + o(h^2) \end{align*}\]\(o(h^2)\) is some function that as \(h \rightarrow 0\), \(o(h^2) \rightarrow 0\) is negligible compared to \(h^2\). Plugging in our Taylor approximation for \(f(hu + s)\):
\[\begin{align*} \mathbf{E}[\hat{f}_N(s)] &= \int K(u) \left[f(s) + huf'(s) + \frac{h^2u^2}{2}f''(s) + o(h^2)\right] du \\ &= f(s)\underbrace{\int K(u) du}_\text{[1], = 1} + hf'(s)\underbrace{\int uK(u) du}_\text{[1], = 0} + \frac{h^2}{2}f''(s)\int u^2 K(u)du + o(h^2) \\ &= f(s) + \frac{h^2}{2}f''(s)\int u^2 K(u)du + o(h^2), \quad \text{Thus...} \\ \textbf{Bias}(\hat{f}_N(s)) &= E[\hat{f}_N(s)] - f(s) = \frac{h^2}{2}f''(s)\underbrace{\int u^2 K(u)du}_\text{constant} + \underbrace{o(h^2)}_\text{bounded} \\ &= \frac{t \cdot h^2}{2}f''(s) + o(h^2), \quad \boxed{t = \int u^2 K(u)du} \end{align*}\]From this we can see that the lower bandwidth \(h\) we choose, the less bias we get. We also get the inisght that bias is highest at points \(s\) where the curvature is very high, such as at a sharp peak. This is pretty apparent when we think of high KDE tries to smooth around these rough edges in the data.
Variance
Similarly, we find the upper bound for variance of estimated density, \(\hat{f}_N\) at some point \(s\):
\[\begin{align*} \mathbf{Var}(\hat{f}_N(s)) &= \mathbf{Var} \left(\frac{1}{Nh} \displaystyle \sum_{i = 1}^{N} K \left(\frac{X_i - s}{h}\right)\right) \\ &= \frac{1}{Nh^2} \left(\mathbf{E}\left[ K^2 \left( \frac{X - s}{h}\right) \right] - \mathbf{E}\left[ K \left( \frac{X - s}{h}\right)\right]^2\right), \; K \text{ is symmetric about } s \text{ [1]}\\ &\leq \frac{1}{Nh^2} \mathbf{E}\left[ K^2 \left( \frac{X - s}{h}\right) \right] \\ &= \frac{1}{Nh^2} \int K^2 \left( \frac{x - s}{h}\right)f(x) dx \end{align*}\]We now substitute \(u = \frac{x - s}{h}\) and approximate \(f(hu + s)\) via \(1^{st}\) order Taylor series expansion about \(h = 0\):
\[\begin{align*} \mathbf{Var}(\hat{f}_N(s)) &\leq \frac{1}{Nh^2} \int K^2(u)f(hu + s)hdu \\ &= \frac{1}{Nh} \int K^2(u)f(hu + s)du \\ &= \frac{1}{Nh} \int K^2(u)[f(s) + huf'(s) + o(h)]du \\ &= \frac{1}{Nh} \bigg(f(s)\int K^2(u) du + hf'(s)\underbrace{\int uK^2(u) du}_\text{[1], = 0} + o(h)\bigg) \\ \mathbf{Var}(\hat{f}_N(s)) &\leq \frac{f(s)}{Nh}\underbrace{\int K^2(u) du}_\text{constant} + \underbrace{o\bigg(\frac{1}{Nh}\bigg)}_\text{bounded} \\ &= \frac{z}{Nh}f(s) + o\bigg(\frac{1}{Nh}\bigg), \quad \boxed{z = \int K^2(u) du} \end{align*}\]Because \(\frac{1}{Nh}\) is the other function of \(h\) in this expression, we say that as \(h \rightarrow 0\) and \(N \rightarrow \infty\), \(o\left(\frac{1}{Nh}\right)\) is some function that is negligible compared to \(\frac{1}{Nh}\). We observe that the variance of our kernel density estimate \(\mathrm{Var}(\hat{f}_N(s))\) is high at points of high density in the true distribution, \(f(s)\). We also see that increasing either sample size or bandwidth decreases this upper bound.
Bringing it Together: MSE
Knowing both bias and variance of KDE predictors, it’s natural to look towards computing the Mean Squared Error (MSE).
\[\begin{align*} \textbf{MSE}(\hat{f}_N(s)) &= \textbf{Bias}^2(\hat{f}_N(s)) + \textbf{Var}(\hat{f}_N(s)) \\ &= \left(\frac{th^2}{2}f''(s) + o(h^2) \right)^2 + \frac{z}{Nh}f(s) + o\left(\frac{1}{Nh}\right); \quad \boxed{t = \int u^2 K(u)du, \; z = \int K^2(u) du} \\ &= \frac{t^2h^4}{4}\left[f''(s)\right]^2 + \frac{z}{Nh}f(s) + o(h^4) + o\left(\frac{1}{Nh}\right) \end{align*}\]The Mean Squared Error can be treated as a risk function similar to what we saw in Bayesian predictors. \(\frac{t^2h^4}{4}\left[f''(s)\right]^2 + \frac{z}{Nh}f(s)\) is the \(\textbf{Asymptotic Mean Squared Error (AMSE)}\). With this it’s quite straightforward to optimize with respect to \(h\).
\[\begin{align*} \frac{\partial}{\partial h} \textbf{AMSE}(\hat{f}_N(s)) &= \frac{\partial}{\partial h}\left(\frac{t^2}{4}\left[f''(s)\right]^2\right)\mathbf{h^4} + \left(\frac{z}{N}f(s)\right)\mathbf{\frac{1}{h}} \\ &= \left(t^2\left[f''(s)\right]^2\right)\mathbf{h^3} - \left(\frac{z}{N}f(s)\right)\mathbf{\frac{1}{h^2}} \\ 0 &= \left(t^2\left[f''(s)\right]^2\right)\mathbf{h^5} - \left(\frac{z}{N}f(s)\right) \\ \mathbf{h_{opt}} &= \left(\frac{zf(s)}{Nt^2\left[f''(s)\right]^2}\right)^{\frac{1}{5}} = \boxed{C_1 N^{-\frac{1}{5}}} \end{align*}\]5. Choosing Bandwidth
Bandwidth is similar to bin width in histograms. Bandwidth determines how smooth the KDE curves can be. If the chosen bandwidth is very small, the curve will be high variance; this case is called undersmoothing. If the chosen bandwidth is too large, however, the curve will have high bias and we are oversmoothing the curve.
Because an appropriate size of bandwidth yields optimal results of estimation, bandwidth selection is a very important topic. If we choose a correct bandwidth, we will be able to estimate the underlying distribution, which neither wiggles too much (with a very small bandwidth) nor loses its characteristics (with a very large bandwidth).
Although there are many different bandwidth selection methods, the main idea of these methods is to minimize the asymptotic mean integrated square error (AMISE). You might’ve thought that we’ve already found the optimal \(h\), but previously we only found the \(h_{opt}\) for a single point \(s\). To do this for the entire distribution we must optimize on the same AMSE just integral along all value of the distribution. We provide the tools below and leave this as a simple exercise for the reader:
\[ \textbf{MISE}(\hat{f}_N(s)) = \underbrace{\int \left(\frac{t^2h^4}{4}\left[f''(s)\right]^2 + \frac{z}{Nh}f(s) \right) dx}_{\textbf{AMISE}(\hat{f}_N(s))} + o\left(\frac{1}{Nh}\right) \]
In the end, you should find \(h_{opt}\) is dependent on the overall curvature of the underlying distribution \(\int \left[f''(x)\right]^2 dx\). Despite the age of the KDE concept, many of the advances in KDE are within the last decade in the field of bandwidth selection. If you find a good way to estimate \(\textbf{AMISE}\) or the overall curvature, \(\int \left[f''(x)\right]^2 dx\), prepare to get published. See Wang and Zambom (2019) and Goldenshluger, Lepski, and others (2011).
References
Goldenshluger, Alexander, Oleg Lepski, and others. 2011. “Bandwidth Selection in Kernel Density Estimation: Oracle Inequalities and Adaptive Minimax Optimality.” The Annals of Statistics 39 (3). Institute of Mathematical Statistics: 1608–32.
Parzen, Emanuel. 1962. “On Estimation of a Probability Density Function and Mode.” The Annals of Mathematical Statistics 33 (3). JSTOR: 1065–76.
Rosenblatt, Murray. 1956. “Remarks on Some Nonparametric Estimates of a Density Function.” The Annals of Mathematical Statistics. JSTOR, 832–37.
Wang, Qing, and Adriano Z Zambom. 2019. “Subsampling-Extrapolation Bandwidth Selection in Bivariate Kernel Density Estimation.” Journal of Statistical Computation and Simulation. Taylor & Francis, 1–20.
Wasserman, Larry. 2006. All of Nonparametric Statistics. Springer Science & Business Media.